05.04 Why Python is the Leading Language in Data Analytics?¶
This is better seen by action rather than words, let's perform a simple analysis and see. Note that we do not have a dataset ready, we will build the dataset on the fly.
Every time I watch a Die Hard movie I get the impression that there's almost no women acting. In other words, I get the impression that everyone in that film is a bunch of middle-aged of blokes hitting each other. We will try to check this statistically: collect data about all five Die Hard movies and plot the ratio of actors and actresses in the cast of each movie.
We will use more imports than normally here,
these libraries are present in either the standard library or most scientific distributions of Python.
Notably,these are all present in the anaconda distribution.
Of course, all of them can be installed with pip.
A quick outline:
time,functoolsandcollectionsare Python standard library utilities for, respectively, time related system calls, functional programming with lists, and extra data structures.requestsis a library for processing HTTP calls with a very, very clean API.bs4(Beautiful Soup 4) is a library to construct a DOM tree (through HTML parsers) and traverse that tree with a simple API.
To describe the functionality of each of these libraries or HTML DOM parsing
is way beyond our scope.
All these libraries are worth investigating but for our purpose
we will only use them to get our data from the web into pandas.
import numpy as np
import pandas as pd
import time
import functools
import requests
from bs4 import BeautifulSoup
We could get the data from a movie database and then work with structured data. Yet, the main objective of this exercise is to work with rather unstructured and dirty data, therefore we will take the HTML data from Wikipedia about these movies. Wikipeida URLs match the title of each movie with underscores instead of spaces.
movies = ['Die Hard', 'Die Hard 2',
'Die Hard with a Vengeance', 'Live Free or Die Hard', 'A Good Day to Die Hard']
url_base = 'https://en.wikipedia.org'
urls = dict([(m, url_base + '/wiki/' + m.replace(' ', '_')) for m in movies])
urls

OK, we have some data in there about the cast of each movie but this is not the full cast. That said, we can assume that the actors present on screen most of the time are on the wikipedia page. Let's write out a handful of assumptions that will help us scope the answer to our problem:
If an actor or actress appears has a lot screen time he/she is more likely to appear on the cast list on wikipedia.
This means that by using the cast for the wikipedia pages consistently we can argue that we have a good model of screen time of the Die Hard movies. In other words, the most significant the actor is in the movie the most likely it is that we can get his name (and wikipedia link) from the cast section.
The same is valid for missing data. The most important is an actor or actress in the movies the most likely is that his/her wikipedia page will be complete.
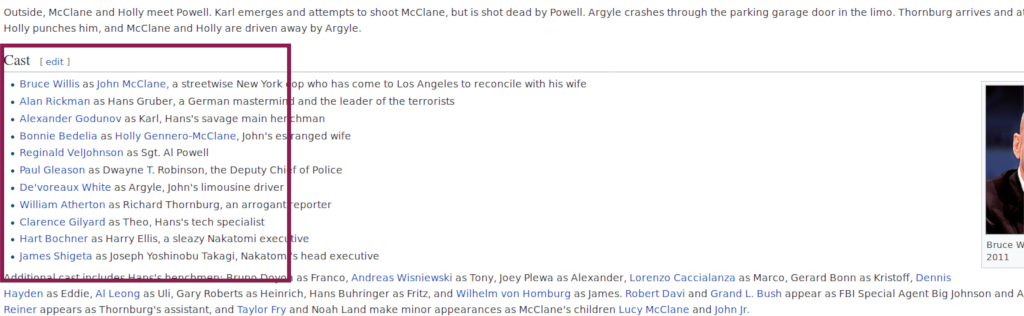
The cast sections of the wikipedia pages are HTML lists <ul>.
We will find those and retrieve all list items which contain a link to a page.
We hope that the link will be to the wikipedia page of the actor/actress
(most of the time it is).
Note: We wait 3 seconds between each call to prevent the wikipedia webservers from kicking us out as an unpolite crawler. On the internet, it is polite to wait a moment between calls to not flood a webserver.
def retrieve_cast(url):
r = requests.get(url)
print(r.status_code, url)
time.sleep(3)
soup = BeautifulSoup(r.text, 'lxml')
cast = soup.find('span', id='Cast').parent.find_all_next('ul')[0].find_all('li')
return dict([(li.find('a')['title'], li.find('a')['href']) for li in cast if li.find('a')])
movies_cast = dict([(m, retrieve_cast(urls[m])) for m in movies])
movies_cast
We place the results in a dictionary of dictionaries. For each movie we have the cast and the web page for each person.
Now we have the links for each actor/actress but again we need to retrieve data from and HTML page. The vcard pane on the right hand side looks promising for data collection: The pane is organized into a key-value structure, and it is an HTML table which is easy to transverse. The data in the pane is still messy but we will worry about that later.
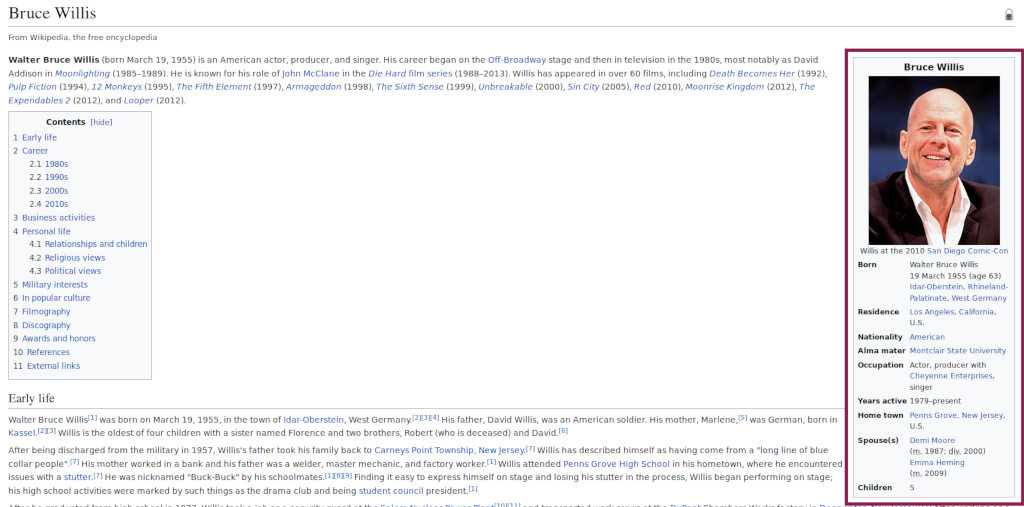
But there's more.
Looking at the raw HTML we can notice a handful data elements that are not displayed
but which may be useful. One such element is bday,
present in the wikipedia pages of several people,
including some of the actors and actresses we are after.
Since we are looking for middle-aged blokes we should retrieve this data as well.
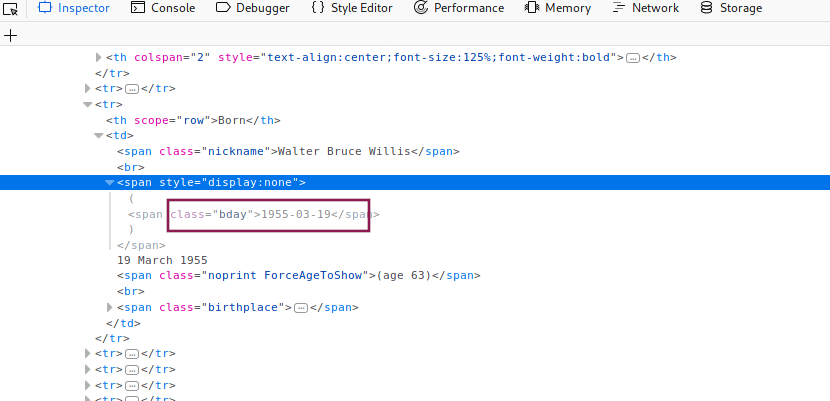
Hidden element on Wikipedia page
All that said, we cannot forget that Wikipedia is not a golden source for data. Data will be dirty, and we will find pages where the vcard section is not present, and it is likely we will not be able to retrieve any data from such pages. One of our assumptions is that the actors and actresses with most screen time will have the most complete wikipedia pages, therefore we should be able to retrieve the most important data.
We also need to think how we are going to structure this data. We have the cast of each movie but several actors appear in more than one movie. Let's add to the data about the actor the movies he has played in. Each time we evaluate the cast of one of the movies we stamp each actor/actress with the movie title.
Since we are using a polite timer, this will take a while to run.
Here the retrieve_actor procedure will give us all mappings
(a dictionary) we can find in the right hand pane and the bday.
We walk the movies_cast dictionary of dictionaries and
retrieve the data for each person,
populating a new dictionary of dictionaries cast.
In the process we mark the movies in which the cast member acted in.
def retrieve_actor(url):
full_url = url_base + url
r = requests.get(full_url)
print(r.status_code, full_url)
time.sleep(3)
soup = BeautifulSoup(r.text, 'lxml')
data = {}
bday = soup.find(class_='bday')
if bday:
data['bday'] = bday.string
vcard = soup.find('table', class_='vcard')
if vcard:
ths = vcard.find_all('th', scope='row')
th_rows = [th.text.replace('\xa0', ' ') for th in ths]
th_data = [th.find_next('td').text.replace('\xa0', ' ') for th in ths]
data.update(dict(zip(th_rows, th_data)))
return data
cast = {}
for m in movies_cast:
for act in movies_cast[m]:
data = retrieve_actor(movies_cast[m][act])
data[m] = 1
if data and act in cast:
cast[act].update(data)
elif data:
cast[act] = data
We got the data!
Well, yes, we got some data, but that does not yet make it useful data.
First of all we need to try to figure out what kind of values we have.
The vcard pane that we parsed was a key-value table,
we should look at what keys we have.
The trick with set and reduce is just a quick functional
way to write a loop looking for unique keys.
keys = [list(cast[i]) for i in cast]
flat_keys = set(functools.reduce(lambda x, y: x + y, keys))
sorted(flat_keys)
That appears to be good enough. Some keys are quite clear as to what they represent (e.g. "Occupation"), others are quite elusive (e.g. "Genres"). One way or another we have a list of keys which we can turn into columns of a data frame. We need to figure out what is the set of all keys in order to know how many columns the data frame will need to have.
We build two data structures: One a list of the actor and actress names, which we will use as the data frame index. And the other data structure as a list of values for every key for every actor.
df_name = []
df_columns = {}
for k in flat_keys:
df_columns[k] = []
for act in cast:
df_name.append(act)
for k in df_columns:
if k in cast[act]:
df_columns[k].append(cast[act][k])
else:
df_columns[k].append(np.nan)
df = pd.DataFrame(df_columns, index=df_name)
df.head()
Now we can operate on this data in pandas directly.
We see a lot of NaNs but we can deal with missing easily.
For the time being let us save our work so we do not lose it.
The to_csv procedure will save the data including the position
of the missing values.
We also give the index a name so when loading the data we can
specify the index to parse by name.
df.index.name = 'webpage_name'
df.to_csv('da-die-hard-newest.csv')
Note that the data collected from a changeable source such as Wikipedia is different every time we collect it. The filename used here is different from the one in the next section where we load the data. That is in order to preserve reproducibility.
If you want to perform the same analysis on the more actual data you have collected, feel free to change the filename. Note that several things will look different from here on in that case. And you are the only one who can deal with them since you are the only one with the data you just collected.